
Windows版のLAMMPSを、ノートPCの内蔵グラフィックで動かしてみます。
2023.12.24追記 デスクトップPC(GPU:GeForce RTX 4060 Ti)での結果を載せました。
GPUパッケージ
LAMMPSをGPUで動かすにはGPUパッケージがインストールされている必要があります。
Windows用のインストーラからインストールした場合はすでに組み込まれています。
パッケージの確認方法については以下の記事で紹介しています。
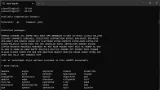
lmp -h で確認すると最初のほうにGPU関係の記述があります。
OS: Windows 11 23H2, Windows ABI 6.2 (9200) on x86_64
Compiler: MinGW-w64 64bit 10.0 / GNU C++ 12.2.1 20221121 (Fedora MinGW 12.2.1-8.fc38) with OpenMP 4.5
C++ standard: C++14
MPI v2.0: Microsoft MPI v10.1.12498.18
Accelerator configuration:
GPU package API: OpenCL
GPU package precision: mixed
KOKKOS package API: OpenMP Serial
KOKKOS package precision: double
Kokkos library version: 3.7.2
OPENMP package API: OpenMP
OPENMP package precision: double
OpenMP standard: OpenMP 4.5
INTEL package API: OpenMP
INTEL package precision: single mixed double
Compatible GPU present: yes計算の実行
計算はLAMMPS公式のベンチマークである in.lj.txt を使用します。
CPUで計算した際の計算方法や結果はこちらの記事をご覧ください。

ではGPU計算のコマンドを実行します。
lmp -sf gpu -pk gpu 1 -in in.lj.txt結果の出力から計算速度にかかわる部分を抜き出すと、
Loop time of 0.125722 on 1 procs for 100 steps with 32000 atoms
Performance: 343615.278 tau/day, 795.406 timesteps/s, 25.453 Matom-step/sCPU単体での計算との比較は後ほど。続いてCPU並列を併用してみます。コマンドはこちらです。
mpiexec -n 4 lmp -sf gpu -pk gpu 1 -in in.lj.txt同様に、速度に関する出力はこちらです。
Loop time of 0.118425 on 4 procs for 100 steps with 32000 atoms
Performance: 364787.840 tau/day, 844.416 timesteps/s, 27.021 Matom-step/s少し速くなっていますが、そもそもの計算負荷が軽すぎるのであまり恩恵がないですね。
CPUとの比較
LAMMPS公式が配布しているWindows用のMSMPIバイナリを使用し、in.ljベンチマークのtimesteps/sの値を比較します。測定の環境は以下の通り。
| ノートPC | デスクトップPC | |
|---|---|---|
| CPU | AMD Ryzen 5 7530U 6コア 12スレッド | AMD Ryzen 7 5700X 8コア 16スレッド |
| RAM | 16GB | 16GB |
| GPU | Radeon Graphics (CPU内蔵グラフィック) | NVIDIA GeForce RTX 4060 Ti |
計算はin.lj 32,000原子の100ステップです。
| 条件 | ノートPC 速度 [timesteps/s] | デスクトップ 速度 [timesteps/s] |
|---|---|---|
| CPU 1プロセス | 83.492 | 97.137 |
| CPU 4プロセス | 329.869 | 333.560 |
| CPU 1プロセス+GPU | 795.406 | 1569.341 |
| CPU 4プロセス+GPU | 844.416 | 926.724 |
内蔵グラフィックなのにそんなに速いの???
という結果になりました。もちろんRTXのほうが速いですが、2倍くらいしか差がありません。
また、計算時間としては1秒以下で終わっており、CPUの瞬間的な動作クロック数はノートPCもデスクトップ並みに高いようで、あまり差がありません。
次に、in.ljを少し書き換えて原子数を増やしました。
variable xx equal 50*$x
variable yy equal 50*$y
variable zz equal 50*$z20倍ずつだったのを50倍ずつに増やして、原子数は32,000原子から500,000原子になりました。
この計算で同様に比較してみます。
| 条件 | ノートPC 速度 [timesteps/s] | デスクトップ 速度 [timesteps/s] |
|---|---|---|
| CPU 1プロセス | 5.693 | 6.086 |
| CPU 4プロセス | 17.651 | 20.316 |
| CPU 1プロセス+GPU | 55.838 | 100.646 |
| CPU 4プロセス+GPU | 51.475 | 101.514 |
こちらは1プロセスでの計算に15秒程度かかる規模ですが、CPUについてはノートもデスクトップも差があまりなく、GPUも2倍くらいの差しかありません。納得いかねえ!
LAMMPS公式のWindowsバイナリはGPU APIがOpenCLで、これがCUDAになるとRTXがさらに速くなるのか、それか計算サンプルが悪くて差が出ないのか… 進展があればまた追記します。
また、今回は非常に短い時間で終わる計算で速度を比較しました。
長時間の計算をした場合はCPUの排熱問題でクロックがダウンすることが予想されますので、ノートとデスクトップの差はそこで出てくると思います。
まとめ
今回はLAMMPSをGPUで動かしてみました。
CPUの内蔵グラフィックでも劇的に速くなり、ちゃんとしたグラフィックボードではそれ以上の速度になりましたが、思ったよりも差が出ませんでした。
WSLでCUDA版LAMMPSを作って試そうと思いますが、なかなか上手くいきません… できたら更新します。
コメント