AMD Ryzen AI Max+ 395搭載のGMKtek EVO-X2を購入しました。RAM128GBモデルなので、VRAMに96GBを割り当てられます。LLMの生成速度を極めるならUbuntuにしてllama.cppをビルドする流れになるのだと思いますが、まずはWindows11で簡単に動作させたいということでOllamaでベストな設定を確認しました。
メインメモリまで食われる問題
Gemma4 31B(コンテキストウィンドウ128kで36GB)を動かそうとしたところ、Windows11のタスクマネージャーのリソース消費に違和感がありました。
- GPU専用メモリ(VRAM)にモデルは載っている
- 共有メモリとメインメモリもかなりのボリュームを消費している
- メインメモリが足りなくなってスワップまで発生してそう
- ollama psコマンドで見るとGPU100%表示
というわけでVRAMとRAMで重複してモデルを読み込んでいるような様子でした。生成速度は遅いわけではないですが、謎にメインメモリを食われていてPCのパフォーマンスは落ちそうでした。
Radeonドライバーの更新で解決
環境変数を変えたりなどいろいろ試しましたが、ドライバの更新だけで解決しました。

Windows用ドライバーをダウンロード を進めていき、インストールが完了後に再度Ollamaを動かすと解決していました。
- GPU専用メモリ(VRAM)にモデルは載っている
- 共有メモリとメインメモリの消費増加はほぼ見られず
解決!
・・・けどしばらく経って再発しました。(この再発の際はスワップは発生してなかったかも知れません)
Modelfileで解決
テキストエディタで次のようなModelfileを作ります。
FROM gemma4:31b
PARAMETER num_gpu 99
PARAMETER use_mmap falseそして ollama create gemma4:31b -f ./Modelfile をすることで、設定を書き加えたgemma4:31bを使うことができます。MMAPを明示的に無効化することで、RAMとVRAMの両方を食われることを防ぐことができました。
Gemma4の生成速度
次のコマンドでGemma4 31BとGemma4 26Bの速度を測りました。
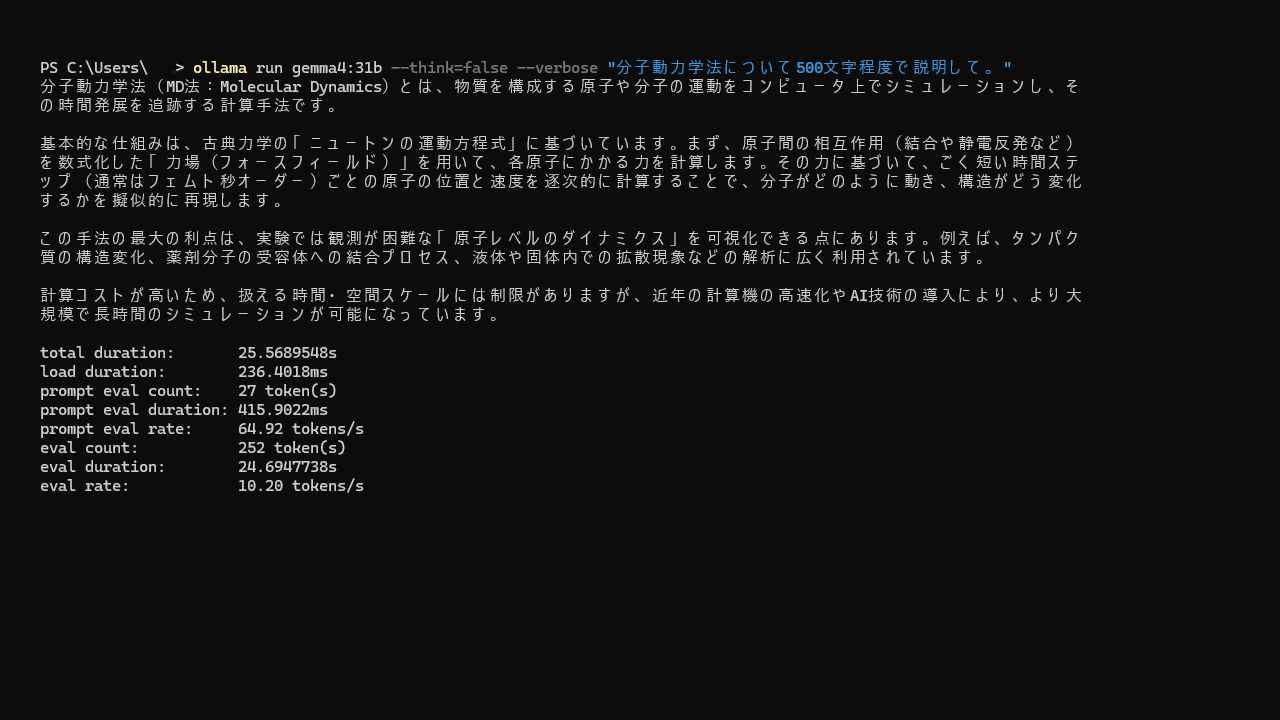
ollama run gemma4:31b –think=false –verbose “分子動力学法について500文字程度で説明して。”
結果は
gemma4:31b 生成速度
total duration: 24.0354535s
load duration: 238.0746ms
prompt eval count: 27 token(s)
prompt eval duration: 514.1173ms
prompt eval rate: 52.52 tokens/s
eval count: 235 token(s)
eval duration: 23.0603665s
eval rate: 10.19 tokens/s
gemma4:26b 生成速度
total duration: 5.3160921s
load duration: 219.0819ms
prompt eval count: 27 token(s)
prompt eval duration: 449.0423ms
prompt eval rate: 60.13 tokens/s
eval count: 248 token(s)
eval duration: 4.536073s
eval rate: 54.67 tokens/s先駆者たちが報告している通りの生成速度になりました。
ちなみに環境変数は OLLAMA_KEEP_ALIVE=-1 しか設定していません。
コメント